Java中实现POJO类的序列化
什么是序列化
序列化:把对象转化为可传输的字节序列过程称为序列化。
反序列化:把字节序列还原为对象的过程称为反序列化。
我们为什么要使用序列化
如果光看定义我想你很难一下子理解序列化的意义,那么我们可以从另一个角度来推导出什么是序列化,那么究竟序列化的目的是什么?
其实序列化最终的目的是为了对象可以 跨平台存储、进行网络传输。我们进行跨平台存储和网络传输的方式是 IO,而我们的 IO 支持的数据格式就是字节数组。
因为我们单方面的只把对象转成字节数组还不行,因为没有规则的字节数组我们是没办法把对象的本来面目还原回来的,所以我们必须在把对象转成字节数组的时候就制定一种规则(序列化),那么我们从IO流里面读出数据的时候再以这种规则把对象还原回来(反序列化)。
如果我们要把一栋房子从一个地方运输到另一个地方去,序列化 就是我把房子拆成一个个的砖块放到车子里,然后留下一张房子原来结构的图纸,反序列化 就是我们把房子运输到了目的地以后,根据图纸把一块块砖头还原成房子原来面目的过程
什么情况下需要序列化
通过上面我想你已经知道了凡是需要进行“跨平台存储”和”网络传输”的数据,都需要进行序列化。
本质上存储和网络传输 都需要经过 把一个对象状态保存成一种跨平台识别的字节格式,然后其他的平台才可以通过字节信息解析还原对象信息。
序列化的几种方式
序列化只是一种拆装组装对象的规则,那么这种规则肯定也可能有多种多样,比如现在常见的序列化方式有:
JDK(不支持跨语言)、JSON、XML、Hessian、Kryo(不支持跨语言)、Thrift、Protostuff、FST(不支持跨语言)
序列化技术选型的几个关键点
序列化协议各有千秋,不能简单的说一种序列化协议是最好的,只能从你的当时环境下去选择最适合你们的序列化协议,如果你要为你的公司项目进行序列化技术的选型,那么主要从以下几个因素。
协议是否支持跨平台
如果你们公司有好多种语言进行混合开发,那么就肯定不适合用有语言局限性的序列化协议,要不然你JDK序列化出来的格式,其他语言并没法支持。
序列化的速度
如果序列化的频率非常高,那么选择序列化速度快的协议会为你的系统性能提升不少。
序列化出来的大小
如果频繁的在网络中传输的数据那就需要数据越小越好,小的数据传输快,也不占带宽,也能整体提升系统的性能。
Java 是如何实现序列化的
前面主要介绍了一下什么是序列化,那么下面主要讲下 Java 是如何进行序列化的,以及序列化的过程中需要注意的一些问题
- java 实现序列化很简单,只需要实现Serializable 接口即可
public class User implements Serializable{
//年龄
private int age;
//名字
private String name ;
public int getAge() {return age;}
public void setAge(int age) {this.age = age;}
public String getName() {return name;}
public void setName(String name) {this.name = name;}
}- 把User对象设置值后写入文件
FileOutputStream fos = new FileOutputStream("D:\\temp.txt");
ObjectOutputStream oos = new ObjectOutputStream(fos);
User user = new User();
user.setAge(18);
user.setName("sandy");
oos.writeObject(user);
oos.flush();
oos.close();- 再把从文件读取出来的转换为对象
FileInputStream fis = new FileInputStream("D:\\temp.txt");
ObjectInputStream oin = new ObjectInputStream(fis);
User user = (User) oin.readObject();
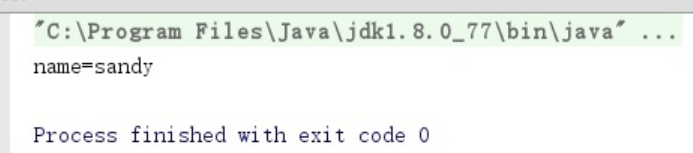
System.out.println("name="+user.getName());输出结果为:name=sandy
以上把 User 对象进行二进制的数据存储后,并从文件中读取数据出来转成 User 对象就是一个序列化和反序列化的过程。
此处可以深入了解一下序列化的原理
JAVA序列化中常见的问题
问题一:static 属性不能被序列化
原因:序列化保存的是对象的状态,静态变量属于类的状态,因此序列化并不保存静态变量。
问题二:Transient 属性不会被序列化
接着上面的案例,我们在 User 里面加上一个 transient 状态的 心情属性 mood;
public class User implements Serializable {
//年龄
private int age;
//名字
private String name;
//心情
private transient String mood;
//省略get set方法
}把 User 对象设置值后写入文件
FileOutputStream fos = new FileOutputStream("D:\\temp.txt");
ObjectOutputStream oos = new ObjectOutputStream(fos);
User user = new User();
user.setMood("愉快");
oos.writeObject(user);
oos.flush();
oos.close();再把从文件读取出来的转换为对象并打印 mood 的值
FileInputStream fis = new FileInputStream("D:\\temp.txt");
ObjectInputStream oin = new ObjectInputStream(fis);
User user1 = (User) oin.readObject();
System.out.println("mood="+user1.getMood());输出结果为:mood=null(原生类型为对应类型的默认值,包装类型为null)
问题三:序列化版本号 serialVersionUID
所有实现序列化的对象都必须要有个版本号,这个版本号可以由我们自己定义,当我们没定义的时候 JDK 工具会按照我们对象的属性生成一个对应的版本号。
版本号有什么用?
其实这个版本号就和我们平常软件的版本号一样,你的软件版本号和官方的服务器版本不一致的话就告诉你有新的功能更新了,主要用于提示用户进行更新。序列化也一样,我们的对象通常需要根据业务的需求变化要新增、修改或者删除一些属性,在我们做了一些修改后,就通过修改版本号告诉反序列化的那一方对象有了修改你需要同步修改。
使用 JDK 生成的版本号和我们自定义的版本号的区别?
JDK 工具生成的 serialVersionUID 是根据对象的属性信息生成的一个编号,这就意味着只要对象的属性有一点变动那么他的序列化版本号就会同步进行改变。
这种情况有时候就不太友好,就像我们的软件一样,使用 JDK 生成的 serialVersionUID,只要对象有一丁点改变 serialVersionUID 就会随着变更,这样的话用户就得强制更新软件的版本,用户不更新就使用不了软件。
而大多数友好的情况也许是这样的,用户可以选择不更新,不更新的话用户只是无法体验新加的功能而已。
也就是说,这种自动生成的版本号可能会受到编译器实现的影响,导致不同编译器生成的版本号不一致,进而导致反序列化失败。
而这种方式就需要我们自定义的版本号了,这样我就可以在新增了属性后不修改 serialVersionUID,反序列化的时候只是无法获取新加的属性,并不影响程序运行。
也就是说,显式定义 serialVersionUID 可以保证序列化类的版本独立性和兼容性。在类的结构发生变化时,手动更新 serialVersionUID 可以告知 Java 虚拟机该类的版本已经发生变化,从而避免版本不匹配的问题,确保反序列化的正确性。
下面用代码测试一下我们的理论:
对象属性序列化版本号不同进行序列化和反序列化
继上面的例子
序列化之前我们设置serialVersionUID=2
public class User implements Serializable {
private static final long serialVersionUID=2;
//年龄
private int age;
//名字
private String name;
}序列化存储User到temp.txt
FileOutputStream fos = new FileOutputStream("D:\\temp.txt");
ObjectOutputStream oos = new ObjectOutputStream(fos);
User user = new User();
user.setName("sandy");
user.setAge(18);
oos.writeObject(user);
oos.flush();
oos.close();然后我们反序列化的时候对象的版本号是serialVersionUID=1
public class User implements Serializable {
private static final long serialVersionUID=1;
//年龄
private int age;
//名字
private String name;
}最后再把从文件数据反序列化取出来
FileInputStream fis = new FileInputStream("D:\\temp.txt");
ObjectInputStream oin = new ObjectInputStream(fis);
User user1 = (User) oin.readObject();
System.out.println("name="+user1.getName());最后执行结果反序列化异常,原因是对象序列化和反序列化的版本号不同导致

对象新增属性,但是版本号相同也可以反序列化成功
序列化的对象信息 这里比反序列化的对象多了个 SEX 属性
public class User implements Serializable {
private static final long serialVersionUID=1;
//年龄
private int age;
//名字
private String name;
//年龄
private int sex;
}序列化存储User到temp.txt
FileOutputStream fos = new FileOutputStream("D:\\temp.txt");
ObjectOutputStream oos = new ObjectOutputStream(fos);
User user = new User();
user.setName("sandy");
user.setAge(18);
user.setSex("女");
oos.writeObject(user);
oos.flush();
oos.close();反序列化的对象信息
序列化的对象信息 这里比序列化的对象少了个 SEX 属性,但版本号一致
public class User implements Serializable {
private static final long serialVersionUID=1;
//年龄
private int age;
//名字
private String name;
}最后再把从文件数据反序列化取出来
FileInputStream fis = new FileInputStream("D:\\temp.txt");
ObjectInputStream oin = new ObjectInputStream(fis);
User user1 = (User) oin.readObject();
System.out.println("name="+user1.getName());最后控制台打印结果正常
结果证明,只要序列化版本一样,对象新增属性并不会影响反序列化对象。
对象新增属性,但是版本号是使用的 JDK 生成序列化版本号
省略代码,最后执行结果报错,原因是序列化和反序列化的版本号不一致造成。
问题四:父类、子类序列化问题
序列化是以正向递归的形式进行的,如果父类实现了序列化那么其子类都将被序列化;
若子类实现了序列化而父类没实现序列化,那么只有子类的属性会进行序列化,而父类的属性是不会进行序列化的。
父类没有实现序列化,子类实现序列化
父类
public class Parent {
//爱好
private String like;
}子类
public class User extends Parent implements Serializable {
//年龄
private int age;
//名字
private String name;
}序列化后再反序列化
//序列化User对象存储到temp.txt
FileOutputStream fos = new FileOutputStream("D:\\temp.txt");
ObjectOutputStream oos = new ObjectOutputStream(fos);
User user = new User();
user.setName("sandy");
user.setAge(18);
user.setLike("看美女");
oos.writeObject(user);
oos.flush();
oos.close();
//从temp.txt 反序列化转为User对象
FileInputStream fis = new FileInputStream("D:\\temp.txt");
ObjectInputStream oin = new ObjectInputStream(fis);
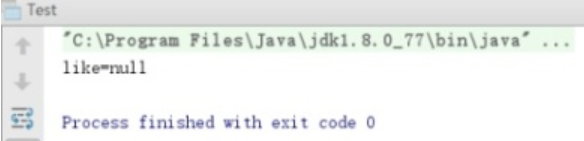
User user1 = (User) oin.readObject();
System.out.println("like="+user1.getLike());最后执行结果,父类属性未被序列化
父类实现序列化,子类不实现序列化
父类
public class Parent implements Serializable{
//爱好
private String like;
}子类
public class User extends Parent {
//年龄
private int age;
//名字
private String name;
}序列化后再反序列化
//序列化User对象存储到temp.txt
FileOutputStream fos = new FileOutputStream("D:\\temp.txt");
ObjectOutputStream oos = new ObjectOutputStream(fos);
User user = new User();
user.setName("sandy");
user.setAge(18);
user.setLike("看美女");
oos.writeObject(user);
oos.flush();
oos.close();
//从temp.txt 反序列化转为User对象
FileInputStream fis = new FileInputStream("D:\\temp.txt");
ObjectInputStream oin = new ObjectInputStream(fis);
User user1 = (User) oin.readObject();
System.out.println("name="+user1.getName());最后执行结果,子类属性序列化正常