

难度:容易
给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。
图示两个链表在节点 c1 开始相交:
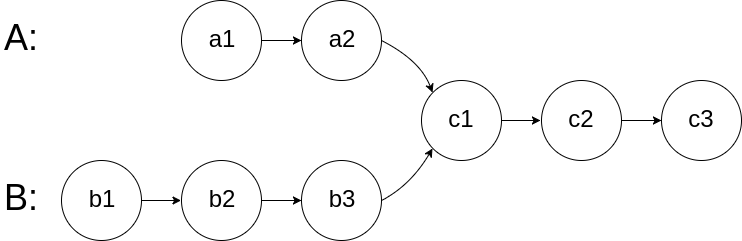
题目数据 保证 整个链式结构中不存在环。
注意,函数返回结果后,链表必须 保持其原始结构 。
自定义评测:
评测系统 的输入如下(你设计的程序 不适用 此输入):
intersectVal- 相交的起始节点的值。如果不存在相交节点,这一值为0listA- 第一个链表listB- 第二个链表skipA- 在listA中(从头节点开始)跳到交叉节点的节点数skipB- 在listB中(从头节点开始)跳到交叉节点的节点数
评测系统将根据这些输入创建链式数据结构,并将两个头节点 headA 和 headB 传递给你的程序。如果程序能够正确返回相交节点,那么你的解决方案将被 视作正确答案 。
示例 1:
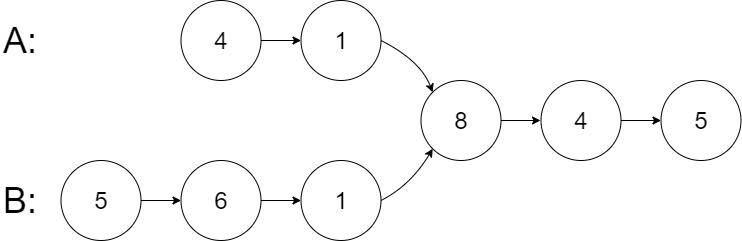
输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,6,1,8,4,5], skipA = 2, skipB = 3
输出:Intersected at '8'
解释:相交节点的值为 8 (注意,如果两个链表相交则不能为 0)。
从各自的表头开始算起,链表 A 为 [4,1,8,4,5],链表 B 为 [5,6,1,8,4,5]。
在 A 中,相交节点前有 2 个节点;在 B 中,相交节点前有 3 个节点。
— 请注意相交节点的值不为 1,因为在链表 A 和链表 B 之中值为 1 的节点 (A 中第二个节点和 B 中第三个节点) 是不同的节点。换句话说,它们在内存中指向两个不同的位置,而链表 A 和链表 B 中值为 8 的节点 (A 中第三个节点,B 中第四个节点) 在内存中指向相同的位置。示例 2:
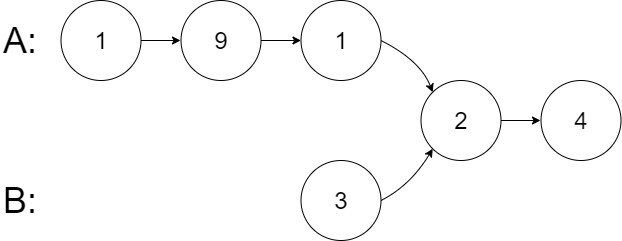
输入:intersectVal = 2, listA = [1,9,1,2,4], listB = [3,2,4], skipA = 3, skipB = 1
输出:Intersected at '2'
解释:相交节点的值为 2 (注意,如果两个链表相交则不能为 0)。
从各自的表头开始算起,链表 A 为 [1,9,1,2,4],链表 B 为 [3,2,4]。
在 A 中,相交节点前有 3 个节点;在 B 中,相交节点前有 1 个节点。示例 3:
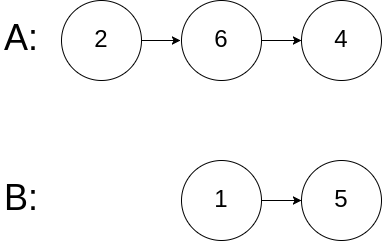
输入:intersectVal = 0, listA = [2,6,4], listB = [1,5], skipA = 3, skipB = 2
输出:null
解释:从各自的表头开始算起,链表 A 为 [2,6,4],链表 B 为 [1,5]。
由于这两个链表不相交,所以 intersectVal 必须为 0,而 skipA 和 skipB 可以是任意值。
这两个链表不相交,因此返回 null 。提示:
listA中节点数目为mlistB中节点数目为n1 <= m, n <= 3 * 1041 <= Node.val <= 1050 <= skipA <= m0 <= skipB <= n- 如果
listA和listB没有交点,intersectVal为0 - 如果
listA和listB有交点,intersectVal == listA[skipA] == listB[skipB]
进阶:你能否设计一个时间复杂度 O(m + n) 、仅用 O(1) 内存的解决方案?
解题思路
这个题要注意一个问题,两个节点相同,所比较的不是两个节点的值是否相等,而是两个节点的 存储地址 是否一致。
并且本题中,如果有一个节点的地址相同了,那么后面的部分默认也是地址相同的。
我一开始想到的暴力做法是:哈希集合 HashSet
我的思路:
- 设定一个哈希集合 hashSet 用来存储链表 headA 里面的节点
- 遍历链表 headA,并将链表 headA 中的每个节点加入哈希集合中。
- 然后遍历链表 headB,对于遍历到的每个节点,判断该节点是否在哈希集合中:
- 如果当前节点不在哈希集合中,则继续遍历链表 headB
- 如果当前节点在哈希集合中,则说明链表 headB 后面的节点都在哈希集合中,即从当前节点开始的所有节点都在两个链表的相交部分,因此目标节点已经找到,返回该节点
- 若链表 headB 遍历结束仍没有找到目标节点,说明两个链表不相交,返回 null
我的代码(哈希集合)
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
HashSet<ListNode> set = new HashSet<>();
//用headA初始化hashSet
for (ListNode cur = headA; cur != null; cur = cur.next) {
set.add(cur);
}
//遍历headB
for (ListNode cur = headB; cur != null; cur = cur.next) {
//找到了相交节点
if (set.contains(cur)) return cur;
}
//链表不相交
return null;
}时间复杂度:O(m+n),其中 m 和 n 是分别是链表 headA 和 headB 的长度。需要遍历两个链表各一次。
空间复杂度:O(m),其中 m 是链表 headA 的长度。需要使用哈希集合存储链表 headA 中的全部节点。
HashSet
结构特点:
- HashSet 是一个没有重复元素的集合。它的底层结构是依靠 HashMap 来实现的。实现方式大致为:通过一个 HashMap 存储元素,元素是存放在 HashMap 的 Key 中,而 Value 统一使用一个 Object 对象。
- HashSet 不保证元素的顺序,而且 HashSet 允许使用 null 元素。
- HashSet 是 非同步的,如果多个线程同时访问一个 HashSet ,而其中至少一个线程修改了该 HashSet ,那么它必须保持外部同步。
- HashSet 按 Hash 算法来存储集合的元素,因此具有很好的存取和查找性能。
使用和理解中需要注意的细节:
HashSet 中是允许存入null值的,但是在 HashSet 中仅仅能够存入一个null值。
HashSet 中存储元素的位置是固定的 HashSet 中存储的元素的是无序的,由于 HashSet 底层是基于 Hash 算法实现的,使用了hashcode,所以 HashSet 中相应的元素的位置是固定的
必须小心操作可变对象(
Mutable Object) 如果一个 HashSet 中的可变元素改变了自身状态使得Object.equals(Object)=true,那么将导致一些问题。
双指针法
思路来源
使用 HashSet 的方法虽然逻辑很简单,而且时间复杂度较低,但是空间复杂度有点高了,我们能不能在常数级空间复杂度的情况下来解决问题呢?
首先注意到,根据题目的意思,如果两个链表相交,那么相交点之后的链表长度应该是相同的。
这是一个关键的信息,联想”二路归并“排序算法中的 对比 步骤,我们如果能让两个链表从 距离末尾相同距离 的位置开始逐个遍历和对比,那么是不是就可以找到这个相同的节点呢?
答案是肯定的,而且很显然,这个 距离末尾相同距离 的位置在最长的情况下,也只能是长度较短的那个链表的头结点位置,这是最靠前的 可能是相交节点 的位置。
等于说,长度较长的链表最前面的一部分是不重要的,是可以直接跳过的,那么算法也就变得清晰了。
记住,我们设置快慢指针的目的是:消除两个链表的长度差。
详细思路
- 设定指针 pA、pB 分别指向链表 A、B 的头节点
- 分别遍历链表 A 和 B,获取链表的长度
- 让较长链表的指针前进到和较短链表指针距离链表尾部距离相同的位置,也就是较短链表的头部位置,这样可以让两个指针形成 齐头并进 的情况
- 两个指针开始一起遍历各自的链表,并逐个对比节点是否相同,若相同,则找到了目标节点,直接返回
- 若链表走到了末尾还没有找到目标节点,则返回 null
代码展示
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
int sizeA = 0;
int sizeB = 0;
ListNode pA = headA;
ListNode pB = headB;
// 获取链表A的长度
for (ListNode cur = headA; cur != null; cur = cur.next) {
sizeA++;
}
// 获取链表B的长度
for (ListNode cur = headB; cur != null; cur = cur.next) {
sizeB++;
}
// 让指针前进到离末尾共同距离的位置
if (sizeA > sizeB) {
for (int i = 0; i < sizeA - sizeB; i++) {
pA = pA.next;
}
} else if (sizeA < sizeB) {
for (int i = 0; i < sizeB - sizeA; i++) {
pB = pB.next;
}
}
// 逐个对比
while (pA != null && pB != null) {
if (pA == pB) return pA;
pA = pA.next;
pB = pB.next;
}
// 链表不相交
return null;
}时间复杂度:O(m+n),其中 m 和 n 是分别是链表 headA 和 headB 的长度。两个指针同时遍历两个链表,每个指针遍历两个链表各两次。
空间复杂度:O(1)
优化后的双指针
我们设定指针 pA、pB 分别指向链表 A、B 的头节点,链表 headA 和 headB 的长度分别是 m 和 n,然后二者同时逐步向后遍历
在二者遍历的时候进行逐个节点的比对,判断是否到达相交点
- 若链表 A 和链表 B 长度相同,且有相交点,则当指针 pA、pB 各自遍历到当前链表末尾之前的时候,就已经可以找到相交点了,此时满足 pA = pB,且二者都不为空,返回 pA 即可
- 若链表 A 和链表 B 长度相同,但无相交点,则当指针 pA、pB 各自遍历到当前链表末尾的时候,此时满足 pA = pB,且二者都为空,说明没有相交点,返回 null
若链表 A 和链表 B 长度不相同,我们假设链表 A 比链表 B 长,即 m > n,则 pB 先达到链表 B 的末尾,此时让 pB 指向链表 A 的开头,二个指针继续遍历,继续对比
当 pA 到达链表 A 的末尾,此时让 pA 指向链表 B 的开头
- 此时 pB 的位置在链表 A 的第 m - n 处,距离链表尾有 m - ( m - n ) = n 的距离,同时 pA 距离链表 B 的末尾也只有 n 的距离,这样同样实现了 消除两个指针的长度差 的目的
两个指针开始向后遍历并逐个比对
- 若链表 A 和链表 B 有相交点,则当指针 pA、pB 各自遍历到当前链表末尾之前的时候,就已经可以找到相交点了,此时满足 pA = pB,且二者都不为空,返回 pA 即可
- 若链表 A 和链表 B 无相交点,则当指针 pA、pB 各自遍历到当前链表末尾的时候,此时满足 pA = pB,且二者都为空,说明没有相交点,返回 null
代码展示
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
if (headA == null || headB == null) {
return null;
}
ListNode pA = headA;
ListNode pB = headB;
while (pA != pB) {
pA = ((pA == null) ? headB : pA.next);
pB = ((pB == null) ? headA : pB.next);
}
return pA;
}时间复杂度:O(m+n),其中 m 和 n 是分别是链表 headA 和 headB 的长度。只需遍历较短的链表两次即可
空间复杂度:O(1)
总结
如果使用 C,C++ 编程语言的话,不要忘了还要从内存中删除这两个移除的节点。
当然如果使用 Java ,Python 的话就不用手动管理内存了。
注意虚拟头节点的引入,可以使代码逻辑更统一。